Enforcing Commit Conventions
A lot ... has ... been ... written about written good commit messages and how it's a very important part of team communication, specially in an open-source setting, and the benefits that such an approach would bring.
But, as most things in programming life, unless there's a clear blueprint and tools that aid with enforcing good patterns, these tend to be ignored, leaving us unable to reap their benefits.
In this post, we'll discuss not only what makes a good commit message, but we will focus on the benefits of following conventions, how to enforce them, and tools that will aid us along the way.
Why follow commit conventions?
Before we dive into the reasons why one would choose to follow a convention at all, we need to start by defining what a convention actually is. Is it some sort of voodo machine-readable text that will make our messages unreadable by humans? Not quite, but... there's a bit of truth in there to start things with, good conventions are machine-readable, and that enables automation, more on that later.
As you've probably figured by now, is just a set of rules you apply to your commit messages, to ensure they're readable, correct, and actionable.
Perhaps the prime example has to be what the Angular team introduced as their convention as part of their contributing guidelines. This has since become such a blueprint that it wouldn't be fair to discuss the topic at all without mentioning them. If you're angsty about an example, you can find them online or you can take a look at this gist.
While some of these rules are semantic in nature (e.g we should describe our changes in present-imperative form), some of them actually help in ways you wouldn't have thought of. Let's start with the most obvious one.
Choosing short, compact and concise messages
This is a borderline hint for you to commit short, compact and concise changes. Always a good practice, by keeping our changes short, focused and not spread across multiple areas, we communicate our intent in a clearer way, makes it easier to find when and why a particular piece of code was introduced, easier to revert if faulty in the future, etc.
Thinking about the nature of a change
Commit conventions encourage you to think about the nature of the change you're making. Are you fixing a bug or introducing a new feature? Are you adding tests? Are you introducing a change that doesn't affect the meaning of the code, or are you refactoring? All of these questions are answered by a single word in your message, and that's a win.
Thinking about the impact of a change
Is my code backwards-compatible? Is there a ticket in our issue-tracking system related to what I'm trying to accomplish?
Thinking about the scope of the change
Your project is certainly composed of many components, which area of your application is the main focus of this change? Does it affect multiple, should I consider splitting it, are my scopes well defined? This also indirectly makes you think about the architecture of your app; the hardest part of system design, but beyond the scope of this post.
Generating changelogs
A good commit convention will enable you to automatically generate changelogs, including grouping by new features, bug fixes, and more.
Automating release versioning
The nature of such specific commit messages, communication of breaking changes, and more, enables tools to automatically suggest a version number increment that adheres to Semantic Versioning.
Conventional Commits
Armed with this knowledge, we're ready to get more concrete about what we mean by commit conventions. Other than briefly mentioning Angular's we haven't really touched upon a concrete implementation of such rules. I'm hoping it's clear by now the benefits are certainly worthwhile, so let's look at some implementations of this.
Perhaps the most abstract one, and yet includes the basis of everything we've discussed, it's outlined in a spec at Conventional Commits.
Before you are scared by the term "spec", thinking about IEEE and such, it's a fairly-readable and common-sense document outlining the process to format your messages. And it basically boils down to this:
<type>[(scope)]: <description>
[optional body]
[optional footer, closed issues, etc]Conventional Commits by itself it's rather permissive when it comes to type
and scope, but as you saw from the brief section on scopes above, you can
extend the tooling that revolves around its ecosystem to be more restrictive.
What's type?
Type is either feat (a new feature for your application) or fix (requires
no explanation). Other types are allowed, as you'll see in the examples.
Scope
Scopes refer to the component of your application affected by this change. You should be familiar with this by now, if so, you can skip to the next section.
A scope intermission
If you're not familiar with scope just yet, perhaps some examples might help.
In commitlint-config-conventional-system we choose (and enforce) a particular set of scopes for a typical user-facing application.
Architecture components
auth:Authentication, login and signup, OAuth, etc.forms:General user input, forms, etc.navigation:Navigation, history and routing.networking:Network-related code, connectivity checks, offline persistence, etc.notifications:Notification code, visible error messages, in-app notifications, push notifications, etc.profile:User profile, friends and/or followers, etc.settings:Settings and preferences, persisted across devices, sometimes device-specific.system:For changes that impact many areas of the system, we generally advice against this.
Platform & Extras
For completeness, if you're building a multi-platform application, it would make sense to allow scopes identifying the platform. As such:
core: Shared code, platform-independent, the "core" of your application.native,desktopandweb: Mobile, desktop and web platforms.
Finally, there are changes that are part of the infrastructure of the app, which should be
self-explanatory: build, deps, packaging and release.
Commit Message Examples
Now that we've glossed over commit types, and scopes, it would make sense to see some examples. The Conventional Commits document doesn't point out to any (yet), but we can always take a look at some real world-ish examples, can't we?
$ git commit -m 'feat(settings): add read-only display of user email'
$ git commit -m 'fix(schema): convert Unix timestamps to proper dates'
$ git commit -m 'chore(deps): upgrade flow-bin'
$ git commit -m 'docs(README): add Docker installation instructions'
$ git commit -m 'refactor(system): remove async function on ErrorScreen'
$ git commit -m 'test: add FlopFlip mock'
$ git commit -m 'perf(schema): add DataLoader for categories'Slightly more complicated examples would include an optional body and footer. In the optional body you would describe your changes in a more detailed fashion, and you'd use the optional footer to communicate breaking changes, reference issue numbers, etc.
You would commit these with git commit -v or one of the tools we mention later.
feat(settings): add Notifications button
Allow users to toggle particular notifications by app section. Sets user
properties to identify whether to send notifications and reminders to particular
user, and enables (un)targeting via Audience settings.
Closes: #155feat(networking): remove file upload from server
Removes file upload...
BREAKING CHANGE: Server no longer does file uploads. We expect `file` fields
in mutations...
Closes: #166The last example in particular is very interesting, as it communicates a breaking
change that (coupled with the right tools) should result in a MAJOR version bump.
Setting up a project for conventional messages
If you've read this far, I assume you'd be interesting in knowing how we can put a practical approach to what we've discussed and enforce commit conventions across a project. We'll assume a JavaScript project, but I'm sure there are similar tools for your language of choice.
Pre-requisites
You'll need NodeJS in order to follow part of the tutorial. Also, an existing Git repository or a brand new for testing purposes would be necessary.
Let's start by installing commitlint,
a command-line tool to lint commit messages. We'll also install a commit convention,
which is basically a set of rules to be enforced by this tool. I recommend
commitlint-config-conventional, commitlint-config-angular, or commitlint-config-conventional-system.
npm install -g @commitlint/cli @commitlint/config-conventionalThen we need to create a configuration file. There are many places where you
can put this config, but for simplicity we'll use the recommended approach and
place it at the root of our repository, in a file named commitlint.config.js:
module.exports = {
extends: ['@commitlint/config-conventional'],
};With that in place, let's test it:
$ echo "foo:bar" | commitlint
⧗ input: foo: bar
✖ type must be one of [build, chore, ci, docs, feat, fix, perf, refactor, revert, style, test] [type-enum]
✖ found 1 problems, 0 warningsInvoking this manually before we run our code is going to be tedious, so we're
gonna make some changes to our package.json to streamline our workflow.
{
"name": "commitlint-test",
"version": "0.0.0-development",
"private": true,
"scripts": {
"commitmsg": "commitlint -e $GIT_PARAMS"
}
}We're going to use Husky, a git hooks
tool, to ensure our messages are formatted correctly. If it's not, the attempt to
commit will fail. That is the purpose of our commit section. We will install it,
and save it as a development dependency, as follows:
$ npm install -D huskyWe can verify that now, by trying to commit with an improper message (according to our config):
$ git commit -m 'test'
husky > npm run -s commitmsg (node v9.5.0)
⧗ input: test
✖ message may not be empty [subject-empty]
✖ type may not be empty [type-empty]
✖ found 2 problems, 0 warnings
husky > commit-msg hook failed (add --no-verify to bypass)As you can see, commitlint is complaining that our message is empty,
as well as our type (since we didn't include a colon).
Let's try with a proper message this time:
$ git commit -m 'feat: initial release'
husky > npm run -s commitmsg (node v9.5.0)
⧗ input: feat: initial release
✔ found 0 problems, 0 warnings
[master (root-commit) c49e633] feat: initial releaseAwesome! Now this will prevent us from commiting invalid messages. It is hard at the beginning to remember these rules though. In the next section, we'll look at some tools that might help us with that.
Using commitizen to prompt for commit messages
It would be handy if we could format our message in an structured way, before
being warned if it was wrong after the fact. That, is one of the many purposes
of commitizen, and fortunately commitlint
includes an adapter for it.
Let's start by installing it globally:
$ npm install -g @commitizen/cliAnd then add the commitlint adapter:
npm install -D @commitlint/promptBack in our package.json, we need to point commitizen to our adapter:
{
"name": "commitlint-test",
"version": "0.0.0-development",
"private": true,
"scripts": {
"commitmsg": "commitlint -e $GIT_PARAMS"
},
"config": {
"commitizen": {
"path": "@commitlint/prompt"
}
}
}And now, we can commit with git cz (which I've aliased to gcz in my shell
config), and we'll be interactively prompted for all the information we need for
our commit message (including useful hints and tab completion!). Here's an example session:
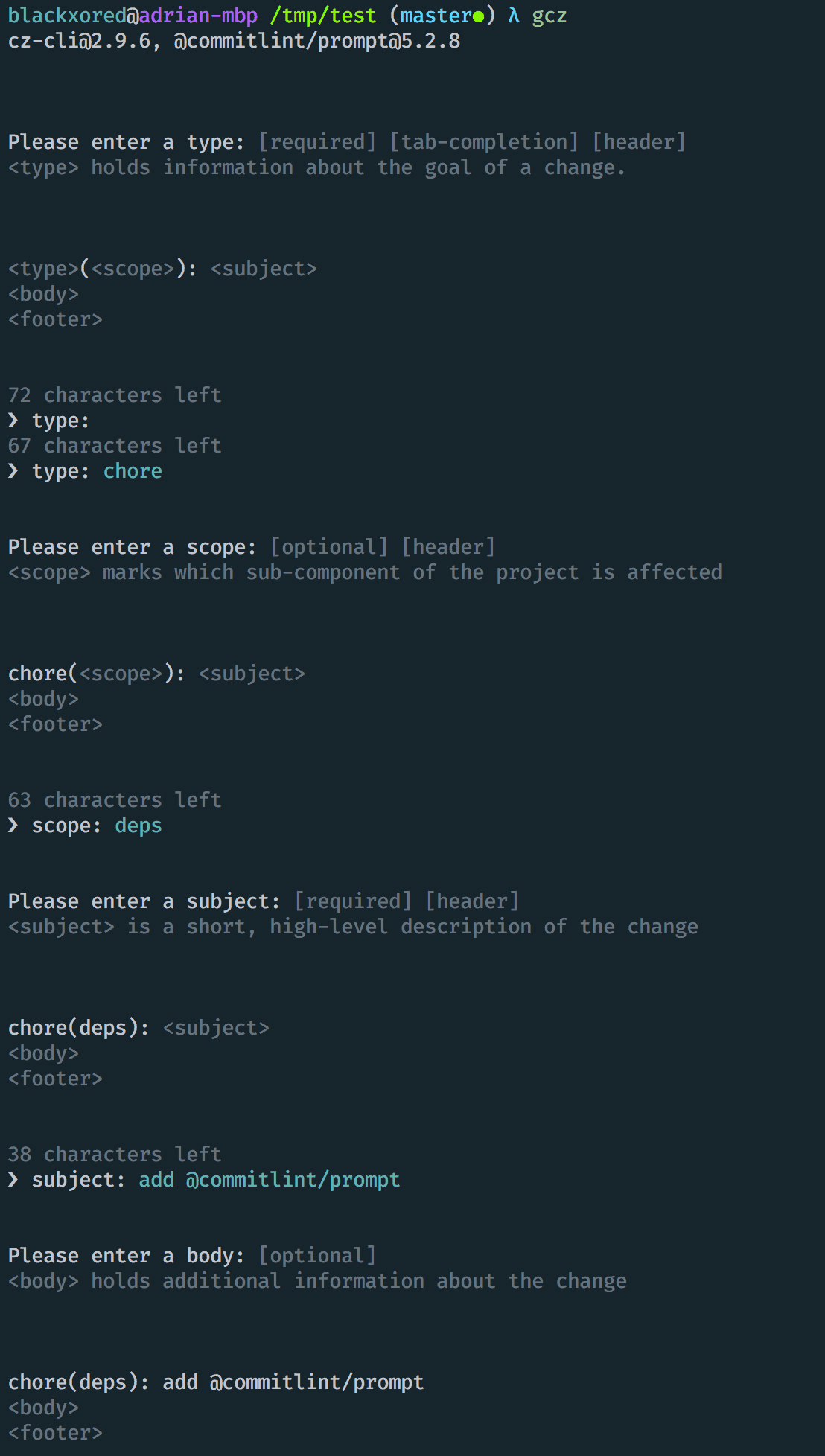
Conclusion
Enforcing commit message conventions will help your team communicate better, track bugs, isolate changes, and more as we've described. If you're interested in learning more, including automation, I'd recommend you take a look at conventional-changelog, standard-version, semantic-release, and lerna, in addition to commitlint's documentation, and devise new ways to automate your workflow.